Datasets
You can find a a selection of datasets maintained by us on the following pages. All data is only for research purposes, unless stated differently. Please make sure to reference the authors properly when using the data.
ACDC: The Adverse Conditions Dataset with Correspondences for Semantic Driving Scene Understanding

ACDC is a large-scale driving dataset for training and testing semantic segmentation algorithms on adverse visual conditions. It comprises a large set of 4006 images which are evenly distributed between fog, nighttime, rain, and snow. Each adverse-condition image comes with a high-quality fine pixel-level semantic annotation, a corresponding image of the same scene taken under normal conditions and a binary mask that distinguishes between intra-image regions of clear and uncertain semantic content. A benchmark suite and evaluation server is provided for the two tasks that are supported by ACDC: standard semantic segmentation and uncertainty-aware semantic segmentation. ACDC serves as a test bed both for supervised semantic segmentation and unsupervised domain adaptation, especially in the normal-to-adverse adaptation setting. Information, dataset and benchmarks for ACDC
Related publications: Christos Sakaridis, Dengxin Dai, and Luc Van Gool. "external page ACDC: The Adverse Conditions Dataset with Correspondences for Semantic Driving Scene Understanding"
arXiv e-prints, abs/2104.13395, April 2021
GeoZurich: Street-side dataset of the city of Zurich

The dataset, named CVL GeoZurich 2018, consists of about 3 million high-quality images, spanning 70 km in the drive-able street network of Zurich. It consists of a rigid 16 camera setup with 4 stereo pairs and 8 additional view points.This dataset is not available for the public. CVL members can get further information here:
Information, download and code for GeoZurich 2018
AirZurich: Aerial imagery dataset of the city of Zurich

The dataset, named CVL AirZurich 2018, consists of about 830 high-quality aerial images, spanning across the city of Zurich. It consists of GPS-registered flyover path and 16-bit RGB TIFF images. This dataset is not available for the public. CVL members can get further information here: Information, download and code for AirZurich 2018
DAVIS: Densely Annotated VIdeo Segmentation 2017

The dataset, named DAVIS 2017 (Densely Annotated VIdeo Segmentation), consists of 150 high quality video sequences, spanning multiple occurrences of common video object segmentation challenges such as occlusions, motion-blur and appearance changes. Each video is accompanied by densely annotated, pixel-accurate and per-frame ground truth segmentation of multiple objects.
external page Information, download and evaluation code of DAVIS 2017
Related publications:
J. Pont-Tuset, F. Perazzi, S. Caelles, P. Arbeláez, A. Sorkine-Hornung, and L. Van Gool , "external page The 2017 DAVIS Challenge on Video Object Segmentation", arXiv:1704.00675, 2017
DAVIS: Densely Annotated VIdeo Segmentation 2016

The dataset, named DAVIS 2016 (Densely Annotated VIdeo Segmentation), consists of fifty high quality, Full HD video sequences, spanning multiple occurrences of common video object segmentation challenges such as occlusions, motion-blur and appearance changes. Each video is accompanied by densely annotated, pixel-accurate and per-frame ground truth segmentation of a single object.
external page Information, download and evaluation code of DAVIS 2016
Related publications:
F. Perazzi, J. Pont-Tuset, B. McWilliams, L. Van Gool, M. Gross, and A. Sorkine-Hornung , "external page A Benchmark Dataset and Evaluation Methodology for Video Object Segmentation", CVPR, 2016.
IMDB-WIKI – 500k+ face images with age and gender labels
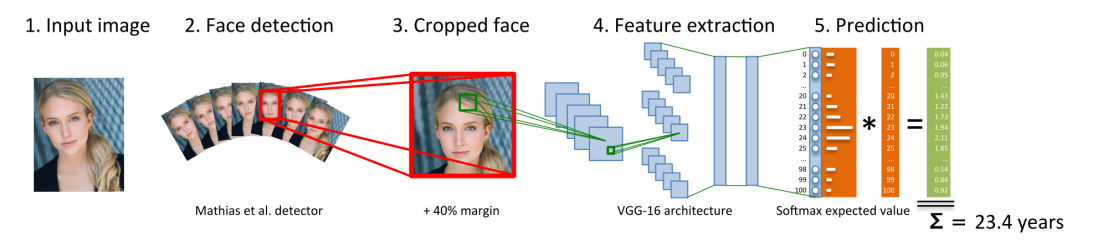
The IMDB-WIKI dataset contains more than 500k face images with gender and age labels for training. We provide pre-trained models for both age and gender prediction. Our method for age estimation was pre-trained on IMDB-WIKI and is the winner (1st place) of the ChaLearn LAP 2015 challenge on apparent age estimation with more than 115 registered teams, significantly outperforming the human reference.
Information and download page for IMDB-WIKI dataset and pre-trained models
Related publications:
Rasmus Rothe and Radu Timofte and Luc Van Gool, "external page Deep expectation of real and apparent age from a single image without facial landmarks", IJCV, 2016.
Rasmus Rothe and Radu Timofte and Luc Van Gool, "external page DEX: Deep EXpectation of apparent age from a single image", ICCVW, 2015.
ETH Synthesizability

A dataset for large-scale texture synthesis. It contains 21,302 texture examples. All of them are annotated in terms of their synthesizability: the ‘goodness’ of the synthesized results by four popular example-based texture synthesis methods.
Information, code and download page
Related publications:
Dengxin Dai; Riemenschneider, H.; Van Gool, L., "external page The Synthesizability of Texture Examples", in Computer Vision and Pattern Recognition (CVPR), 2014.
Food 101

A data set for recognition of pictured dishes. It contains 101 food categories with in total 101'000 images.
Information and download page
ETHZ RueMonge 2014

Semantical 3D models, e.g. of cities are usually derived from classifying 2D images. The 3D challenge pushes the frontiers on 3D modelling and 3D semantic classification. This dataset consists of 700 meters along a street annotated with pixel-level labels for facade details such as windows, doors, balconies, roof, etc. It is the largest and most detailed dataset available including a dense surface and semantic labels for urban classes.
Information and download page for the 3D Challenge
Related publications:
H. Riemenschneider, A. Bodis-Szomoru, J. Weissenberg, L. Van Gool, "external page Learning Where To Classify In Multi-View Semantic Segmentation", European Conference on Computer Vision (ECCV'14).
Apparel classification with Style
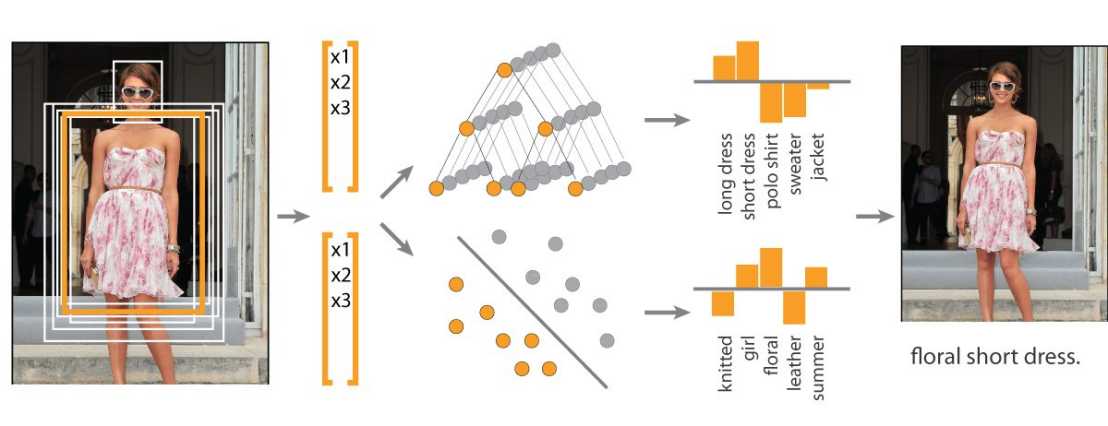
Dataset accompanying the paper Apparel classification with Style.
Information and download page
Related publication:
L. Bossard, M. Dantone, C. Leistner, C. Wengert, T. Quack, L. Van Gool, "external page Apparel Classification with Style", Asian Conference on Computer Vision (ACCV), November 2012.
Biwi Kinect Head Pose Database

Over 15K images of 20 people recorded with a Kinect while turning their heads around freely. For each frame, depth and rgb images are provided, together with ground in the form of the 3D location of the head and its rotation angles.
For any questions regarding the database:
CVL- members: Kristine Haberer
External visitors: external page Gabriele Fanelli
Related publications:
- G. Fanelli, T. Weise, J. Gall, L. Van Gool, "external page Real Time Head Pose Estimation from Consumer Depth Cameras", 33rd Annual Symposium of the German Association for Pattern Recognition (DAGM'11).
- G. Fanelli, J. Gall, L. Van Gool, "external page Real Time Head Pose Estimation with Random Regression Forests",Computer Vision and Pattern Recognition (CVPR'11).
- G. Fanelli, M. Dantone, J. Gall, A. Fossati and L. Van Gool, "external page Random Forests for Real Time 3D Face Analysis", International Journal of Computer Vision (IJCV 2012)
BIWI Walking Pedestrians dataset

Walking pedestrians in busy scenarios from a bird eye view. Manually annotated. Data used for training in our ICCV09 paper "You'll Never Walk Alone: Modeling Social Behavior for Multi-target Tracking"
Download: Download Only annotations (TGZ, 397 KB)
Download: Download Annotations plus videos
ETHZ Shape Classes
A dataset for testing object class detection algorithms. It contains 255 test images and features five diverse shape-based classes (apple logos, bottles, giraffes, mugs, and swans).
Related publications:
- V. Ferrari, F. Jurie, and C. Schmid "external page From Images to Shape Models for Object Detection", International Journal of Computer Vision (IJCV), 2009.
- V. Ferrari, T. Tuytelaars, and L. Van Gool "external page Object Detection by Contour Segment Networks", European Conference on Computer Vision (ECCV), Graz, May 2006.
- T. Quack, V. Ferrari, B. Leibe, L. Van Gool "external page Efficient Mining of Frequent and Distinctive Feature Configurations", International Conference on Computer Vision (ICCV), 2007.
Download: Download ETHZ shape classes (TGZ, 29 MB)
Download: Download ICCV07 paper's training set (GZ, 8.6 MB)
Maintained by external page Vittorio Ferrari
ETHZ Extended Shape Classes

The Extended ETHZ shape classes is a larger database of shape categories, created by merging ETHZ shape classes with Konrad Schindler's 4x50 closed shapes. This is (almost) a superset of each of the two older databases. Please refer to the README for details on the differences and how to use the new larger dataset.
Related publications:
K. Schindler and D. Suter."external page Object Detection by Global Contour Shape", Pattern Recognition, 41(12), 2008.
Download: Download Extended ETHZ shape classes
ETH Face Pose Range Image Data Set
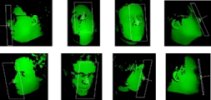
Range images of faces with ground truth used in our CVPR'08 paper "Real-Time Face Pose Estimation from Single Range Images".
Information and Download Page
"Central" Pedestrian Crossing Sequences

Three pedestrian crossing sequences used in our ICCV'07 paper. Each sequence comes with ground-truth bounding box annotations for the objects to be tracked, as well as a camera calibration. The annotation files for the pedestrian crossing sequences contain bounding box annotations for every fourth frame.
Download Download
Contact: Konrad Schindler
Dataset used in our ICCV '07 paper "Depth and Appearance for Mobile Scene Analysis"

The set was recorded in Zurich, using a pair of cameras mounted on a mobile platform. It contains 12'298 annotated pedestrians in roughly 2'000 frames.
Contact: external page Andreas Ess
Zurich Buildings Database

The goal of the ZuBuD Image Database is to share image data sets with researcheres around the world. To facilitate this, we have created this site, which contains over 1005 images about Zurich city building. The detail information about the database can be found on our Technical Report:TR-260.
We will be adding new data to this site as time permits. Furthermore, we will now accept datasets from other researchers, to add to our archive. If you would like to contribute for this, please contact Hao Shao (shao.hao@unaxis.com). The full sized images themselves are stored in PNG (Portable Network Graphics) format.
ZuBuD: Download tar-gzipped (486MB) - Created: April 2003
ZuBuD Query Images: Download tar-gzipped (3,1MB) - Created: April 2003
Download Ground truth mapping (txt) (TXT, 931 Bytes)

ETHZ Personal Event Collection
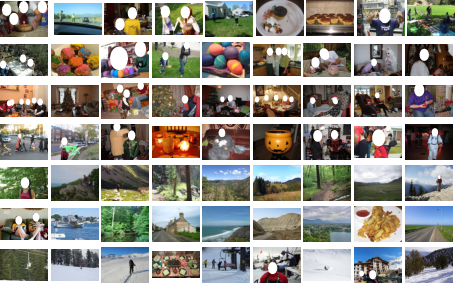
A dataset for recognition of events in personal photo collections. It contains more than 61'000 images in 807 collections, annotated with 14 diverse social event classes.
Information and download page